The github plugin my coworkers asked me not to write.
This blog post was written together with <mclare>, who made coooool visualizations like the picture at the end of the post!
Update: Here’s mclare’s blog post about this, with visualizations!
What’s a Bus Factor or Truck Factor?
According to wikipedia:
The “bus factor” is the minimum number of team members that have to suddenly disappear from a project before the project stalls due to lack of knowledgeable or competent personnel.
Why?
In 2015 or so, my employer had layoffs. One of them was the only contributor to part of the codebase that made money for our company. I remembered reading about Truck Number on the original wiki, so I thought it’d be fun to write a github enterprise plugin that calculates who you can’t afford to fire. I enjoy reading research papers, and found this truck factor research paper.
I started writing the plugin, and talked five minutes on it at our Thursday afternoon lightning talks. My coworkers said it would immediately hit Goodhart’s Law. They saw this as a way for management to easily calculate who you can fire!
What?
The original authors calculated how many people had to be hit by a bus for a bunch of popular GitHub projects to stall. This includes the Linux kernel among others. In the first preprint, they said 80 people would have to leave the project for Linux to stop.
Last week I mentioned this blog post idea to mclare, and she said we should try to reproduce the results and see if the truck factor has improved in the past ten years.
The authors’ github repo is available and still works!
Are we able to reproduce the results?
The Truck Factor research paper links to a github repository! The data from the paper is available as JSON! Their visualization is backed by a CSV we can scrape!
But, we don’t know the date they pulled the data.
The README instructions don’t quite work, and we spent an hour figuring out how to execute the pieces. Fortunately, the issues on the github repository told us how to fix the problem. I wanted results, not an afternoon of debugging their use of awk in shell scripts. mclare got the list of github repos out of the first column of their CSV. We needed to clone them all! We had fun learning about gnu parallel to run a bunch of git clone commands at the same time.
Gnu Parallel
Why does gnu parallel use all the cores when we tell it to use only 8?
We only saw eight git clone processes at a time, but a large number of git index-pack processes that maxed out all 32 cores on my laptop.
I’m guessing git’s index-pack is a forked subprocess and allows parallel to start another git clone?
If you know the answer, send us a message!
Ruby Gems in NixOS
The Truck Factor code uses linguist to filter out files that are only documentation. Later in the paper the authors say that documentation is the best way to keep your project alive, so I’m not convinced that’s good.
In any case, I’m running NixOS and have no experience with Ruby, thus installing Ruby Gems did not fit in the time I had. If you know a good way to install the linguist plugin in a Nix flake, please send me a message! (or even a pull request)
But, how did you recalculate the results?
We forked the original repository on github, cloned it locally, and puzzled our way through the README.
We used mvn package to compile the Java source into a jar, and tried each of the steps on the numpy github repository.
Then we were ready to recalculate all the things.
mclare downloaded the CSV from the authors’ visualization and we converted the first column into a list of github repositories. I started with a for loop, but mclare switched to gnu parallel, because it’s cool. Also because everything gets done faster.
# clone the repositories
parallel -j 8 git clone ::: $(cat ../meta/repo_list.txt)
# change into the directory so you don't get the awk error
cd gittruckfactor/scripts
# scrape out all the git commit info
for x in ../../repos/*; do ./commit_log_script.sh $x; done;
# run the java code that ingests the scraped commit data
for x in ../repos/*; do dirname $x >> ../results.txt && echo java -jar ./target/gittruckfactor-1.0.jar $x $x >> ../results.txt; done;I have a fast gigabit internet connection at home, it took 17.5 minutes to clone all the repos one at a time. Processing each repo took about the same time, eighteen minutes maybe?
Here’s one example output for the linux kernel repository:
linux
TF = 12 (coverage = 49.98%)
TF authors (Developer;Files;Percentage):
Linus Torvalds;5712;6.59
Mauro Carvalho Chehab;2479;2.86
Rob Herring;1313;1.51
Thomas Gleixner;1228;1.42
Krzysztof Kozlowski;1222;1.41
Ben Skeggs;1211;1.40
Arnaldo Carvalho de Melo;911;1.05
Greg Kroah-Hartman;852;0.98
David Howells;718;0.83
Ian Rogers;599;0.69
Masahiro Yamada;598;0.69
Takashi Iwai;581;0.67
Problems
<mclare> This calculation neglects the review process. As you go up the career ladder, developers should do more review and less hands on keyboard.
Further Work
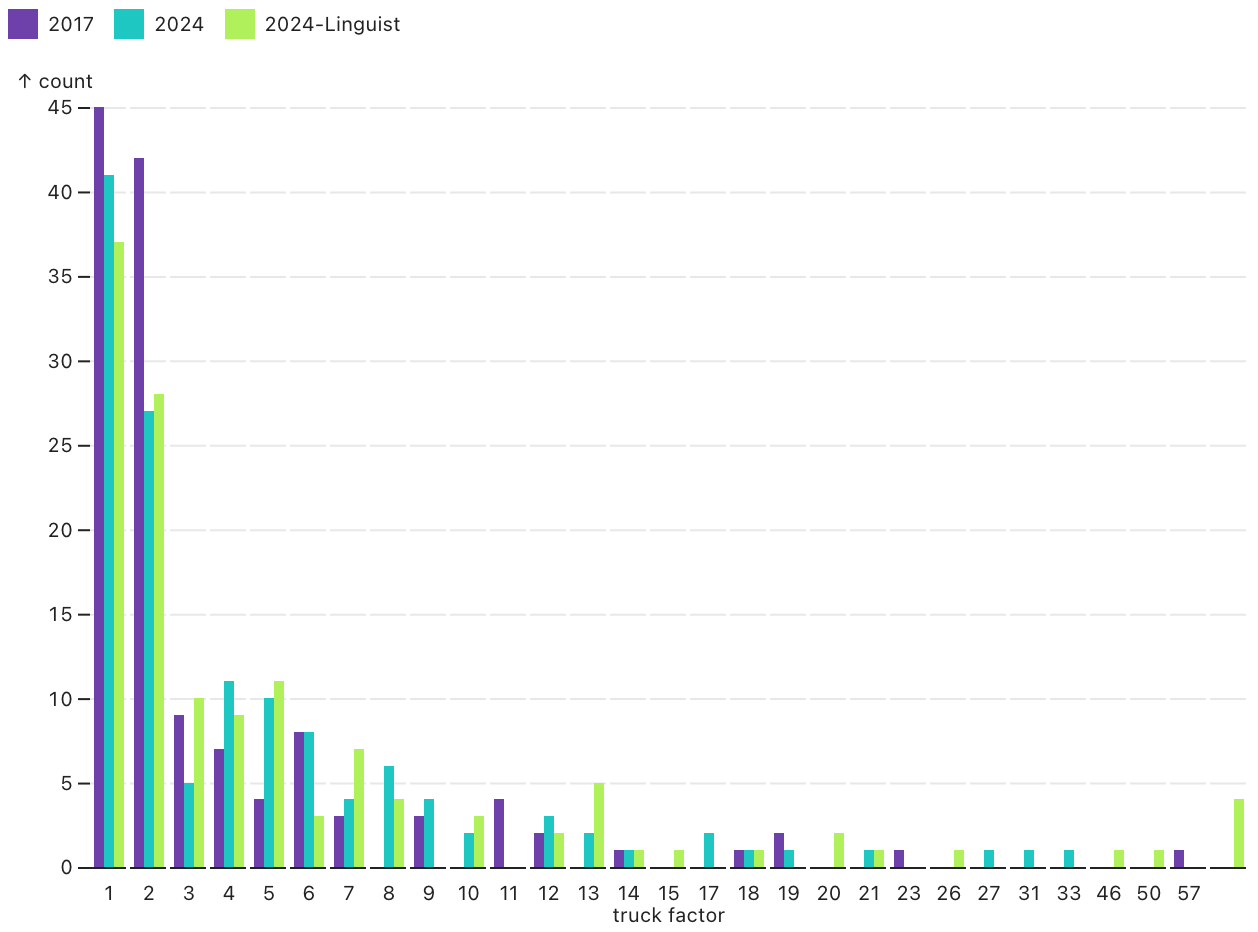
Conclusion - Bus Factors got scarier.
The biggest question we both had was, did it get any better?
I’m gonna say no, it’s gotten worse. The 2015 preprint of this paper gave the linux kernel a truck factor of ninety! The full publication gave that same repository a truck number of fifty seven.
Without the linguist plugin to filter out documentation and third party libraries, we got a truck factor of twelve for the Linux kernel repository. After mclare installed the plugin on her system, she got a truck factor of eight for the Linux kernel.
This is not an improvement.
If you want more articles on this subject, send us a message!
Visualize!
For more visualizations and nifty details, check out mclare’s blog.